Feedback Motion Planning
Throughout these notes we have been developing core ideas from motion planning (especially trajectory optimization and sampling-based planning) and for feedback control (e.g. linear and nonlinear policies). Of course these two lines of work are deeply connected. If you have a trajectory planner that can run fast enough to be evaluated at every control time step (e.g. model-predictive control), then the planner can become a policy. Of course, the opposite is true, too. If you have a policy then you can simulate it forward to generate a trajectory plan.
In the last chapter we started explicitly considering robustness and uncertainty. This complicates the story (but in a beautiful way!). Feedback controllers can be robust, or not, but the planners we've built so far start to struggle. What does it mean for a trajectory to be robust? If we're using $\bx(\cdot), \bu(\cdot)$ to represent a trajectory plan, then the presence of noise can make the plan infeasible. Planning without considering the noise/uncertainty and then stablizing that plan can work in the simple cases, but richer connections are possible.
Parameterized feedback policies as "skills"
When I first introduced the notion of a controller, the job for the controller was to e.g. stabilize a fixed point, or minimize the long-term cost, for all possible initial conditions. Motivated initially by the ability to use linearization and linear optimal control to find feedback controllers even for nonlinear systems, we started to admit that some controllers have a more limited applicablity, and to develop tools for estimating their regions of attraction and/or invariant funnels around trajectories.
One of the very original approaches to planning in artificial intelligence research was the Stanford Research Institute Problem Solver (STRIPS) framework. The original STRIPS framework was for discrete states (actually boolean propositions), with the initial state specifid by a set of propositions and the goal state specified by another set of propositions. Most importantly for our discussion here, the "dynamics" were given by a set of actions (or "skills") which were defined by a set of preconditions (what propositions must be satisfied for the skill to be executed), and a set of postconditions (what propositions will be true if the action is executed).
I'll credit
The field of automated reasoning / task-level planning has evolved dramatically
since the introduction of STRIPS. The planning domain definition language (PDDL)
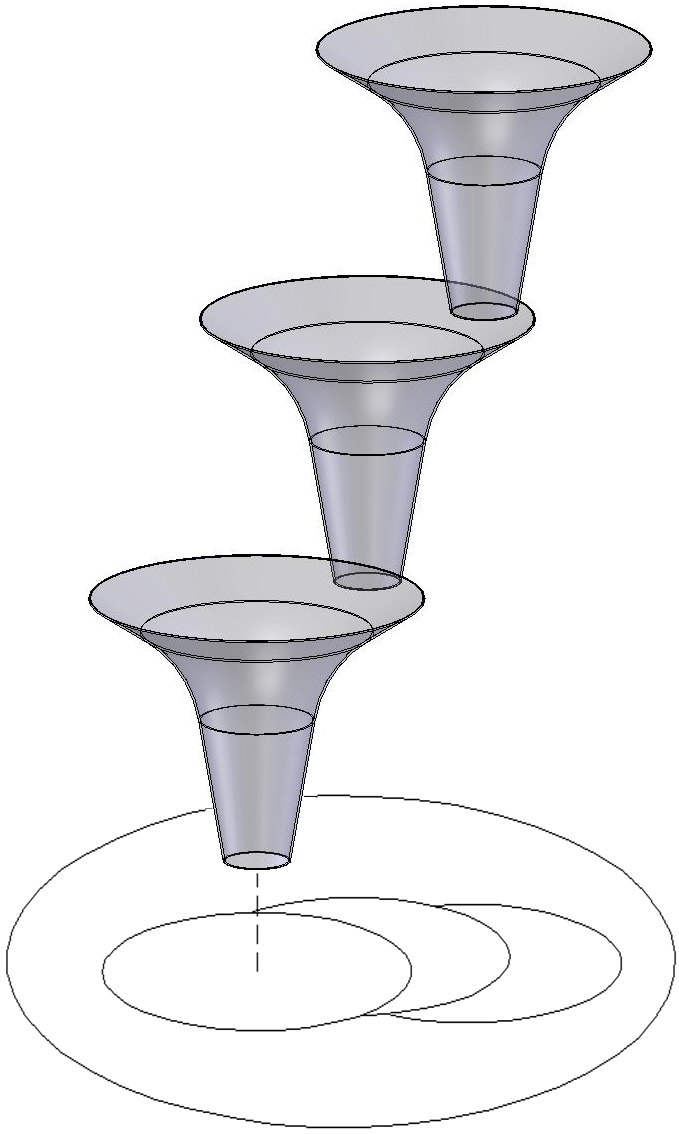
This idea of planning with primitives which are feedback controllers instead of trajectories is potentially very powerful. Let me emphasize one of the key points: trajectories can't be robust, but funnels can.
The rules of composition
Imagine I have two controllers, $\pi_1(\bx)$ and $\pi_2(\bx)$, each equipped with a corresponding function $V_1(\bx)$ and $V_2(\bx)$ which has been certified to satisfy the Lyapunov conditions over their respective sublevel sets, $V_1(\bx) \le \rho_1$, $V_2(\bx) \le \rho_2.$
Let's remember a slightly subtle point. If $\dot{V} \prec 0$, then I'm guaranteed to move down the Lyapunov function, but if $\dot{V} \preceq 0$, then my Lyapunov function only guarantees invariance. For robust stability (again unknown disturbances or modeling errors), it might be unlikely that we can achieve true asymptotic stability. However the cartoon illustration with the funnels above may still be very reasonable. It requires that we have $0 \le \bar{\rho}_{i} \le \rho_i$ such that $$\bar\rho_{i} \le V_i(\bx) \le \rho_i \rightarrow \dot{V}_i(\bx) \prec 0.$$ In words, we would like to have some (asymptotic) convergence from the initiation set $V_i(\bx) \le \rho_i$ to a smaller invariant set $V_i(\bx) \le \bar\rho_i.$ Then we can guarantee that a higher-level planner/controller can transition from executing skill $i$ to executing skill $j$ if $V_i(\bx) \le \bar\rho_i \rightarrow V_j(\bx) \le \rho_j$. For polynomial Lyapunov functions, one can certify these containment conditions using sum-of-squares optimization with the S-procedure; for quadratic Lyapunov functions this reduces nicely to ellipsoidal containment.
The other form of Lyapunov functions which we have studied are the time-varying Lyapunov functions associated e.g. with stabilizing a trajectory. In this case, if the Lyapunov conditions, $\dot{V}(t, \bx) \le \dot\rho_i(t)$, are satisfied for all $\{t, \bx | V_i(t, \bx) = \rho_i(t), t_0 \le t \le t_f \},$ and the underlying dynamics are time-invariant, then it is sufficient to satisfy the containment conditions $V_i(t_i,\bx) \le \rho_i(t_i) \rightarrow V_j(t_j, \bx) \le \rho_j(t_j)$ for any valid $t_i, t_j.$
Pendulum: transitioning from swing-up to balance
Parameterized controllers and Lyapunov functions
We can similarly extend our notion of a continuous feedback skills to include parameterized skills/funnels, for instance when the skills are "goal-conditioned".
Koditschek's juggling robots
Polynomial parameterizations and SOS. But there are a few special cases that can work out particularly nicely...
Equivariance (cyclic coordinates)
State-dependent Riccati equations (SDRE)
Parameterizing via a nominal trajectory.
Probabilistic feedback coverage
There is a nice way to combine the ideas from sampling-based motion planning with
this idea of (guaranteed) sequential composition with funnels